Assignment #5 - Cats Photo Editing¶
Introduction¶
This assignment requires us to implement techniques that manipulate images on the manifold of natural images. It consists of three parts:
- Inverting a pre-trained generator to find a latent variable that closely reconstructs the given real image.
- Taking a hand-drawn sketch and generating an image that fits the sketch accordingly.
- Generating images based on an input image and a prompt using stable diffusion.
Part 1: Inverting the Generator [30 pts]¶
Deliverables
Show some example outputs of your image reconstruction efforts using
- (1) various combinations of the losses including Lp loss, Perceptual loss and/or regularization loss that penalizes L2 norm of delta,
The following results are obtained by using different combinations of losses on the stylegan model with w+ space:
| Lp Loss Weight | Perceptual Loss Weight | Regularization Loss Weight | Total Loss | Image (1000 iterations) |
|---|---|---|---|---|
| - | - | - | original image |  |
| 10.0 | 0.0 | 0.0 | 0.0 |  |
| 0.0 | 0.01 | 0.0 | 36.688824 |  |
| 10.0 | 0.01 | 0.0 | 46.721054 |  |
| 10.0 | 0.0 | 0.001 | 0.0 |  |
| 0.0 | 0.01 | 0.001 | 37.586491 |  |
| 10.0 | 0.01 | 0.001 | 46.721054 |  |
- (2) different generative models including vanilla GAN, StyleGAN, and
The following results are obtained by using different generative models on the z space, using Lp loss and perceptual loss with 1000 iterations:
| Model | Image |
|---|---|
| original image |  |
| Vanilla GAN |  |
| StyleGAN |  |
- (3) different latent space (latent code in z space, w space, and w+ space).
The following results are obtained by using different latent spaces on the stylegan model, using Lp loss and perceptual loss with 1000 iterations:
| Latent Space | Example 1 | Example 2 |
|---|---|---|
| original image |  |
 |
| z space |  |
 |
| w space |  |
 |
| w+ space |  |
 |
Give comments on why the various outputs look how they do. Which combination gives you the best result and how fast your method performs.
Answer: From the results above, we can tell the results from gan are very unstable. For the loss function, using perceptual loss can help to generate image matching the reference image and the regulation for the delta is not very helpful. For the generative model, StyleGAN is better than Vanilla GAN. For the latent space, w and w+ space can better match the reference image than z space.
The best result is obtained by using the stylegan model with w+ space, Lp loss weight 0.01, perceptual loss weight 10.0, and regularization loss weight 0.0. The method performs 1000 iterations within 30s.
Part 2: Scribble to Image [40 Points]¶
Deliverables
Draw some cats and see what your model can come up with! Experiment with sparser and denser sketches and the use of color. Show us a handful of example outputs along with your commentary on what seems to have happened and why.
The following results come from stylegan model with w+ space using Lp loss and perceptual loss with 1000 iterations:
| Sketch Image | Mask Image | Image |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Answer: For most of the results, the model can generate images that match the mask image and the images have enough details. However, sometimes, the generated images will be similar to the training images(the first one), and sometimes, in order to match the sketch, the generated images will have some unrealistic parts, such as the second one. Besides, the color of the sketch will affect the generated image. For the last example, I use a white background in the sketch and a unusual color for the cat, so the generated image is not very good.
Part 3: Stable Diffusion [30pts]¶
Deliverables
Show some example outputs of your guided image synthesis on at least 2 different input images.
| Input Image | Prompt | strength | steps | Image |
|---|---|---|---|---|
 |
"Grumpy cat reimagined as a royal painting" | 15 | 1000 |  |
|
"Grumpy cat reimagined as a oil painting" | 15 | 1000 |  |
|
"Grumpy cat reimagined as a sketch painting" | 15 | 1000 |  |
 |
"A cute cat covered with some bananas" | 10 | 600 |  |
Furthermore, please show a comparison of generated images using
- (1) 2 different amounts of noises added to the input and
Answer: I think the amounts of noises means the timesteps to add noise. The following results are obtained by using different timesteps to add noise on the input image:
| Input Image | Prompt | strength | steps | Image |
|---|---|---|---|---|
|
"Grumpy cat reimagined as a royal painting" | 15 | 500 |  |
|
"Grumpy cat reimagined as a royal painting" | 15 | 700 |  |
|
"Grumpy cat reimagined as a royal painting" | 15 | 1000 | |
Answer: As the timesteps increase, the generated image will change more according to the prompt. The generated image with 1000 timesteps are more aligned with the prompt than the generated image with 500 timesteps.
- (2) 2 different classifier-free guidance strength values.
Answer: The following results are obtained by using different classifier-free guidance strength values:
| Input Image | Prompt | strength | steps | Image |
|---|---|---|---|---|
|
"A cute cat covered with some bananas" | 5 | 600 |  |
|
"A cute cat covered with some bananas" | 10 | 600 | |
|
"A cute cat covered with some bananas" | 15 | 600 |  |
Answer: As the strength increases, the generated image will change more according to the prompt and be more fine-grained. The generated image with strength 15 is more aligned with the prompt than the generated image with strength 5. The generated image with strength 5 is more abstract than others.
Bells & Whistles (Extra Points)¶
Max of 15 points from the bells and whistles.
- Interpolate between two latent codes in the GAN model, and generate an image sequence (2pt)
Answer: The following results are obtained by interpolating between two latent codes in the stylegan model with w+ space:
| Image src | Image dst | GIF |
|---|---|---|
 |
 |
 |
 |
 |
 |
- Develop a cool user interface and record a UI demo (4 pts). Write a cool front end for your optimization backend.
Answer: I use python built-in tkinter to develop a simple user interface. The following is the screenshot of the interface:

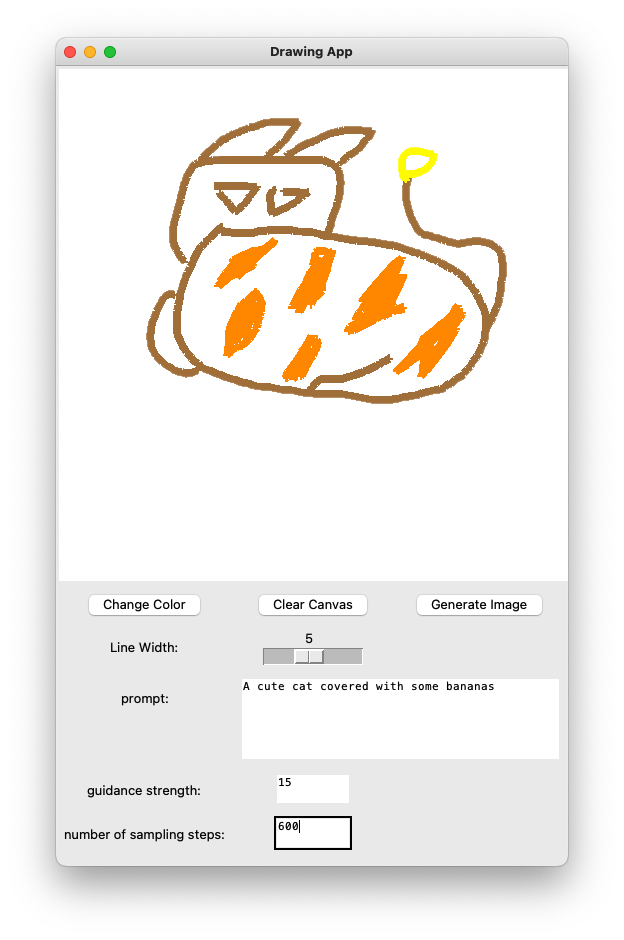
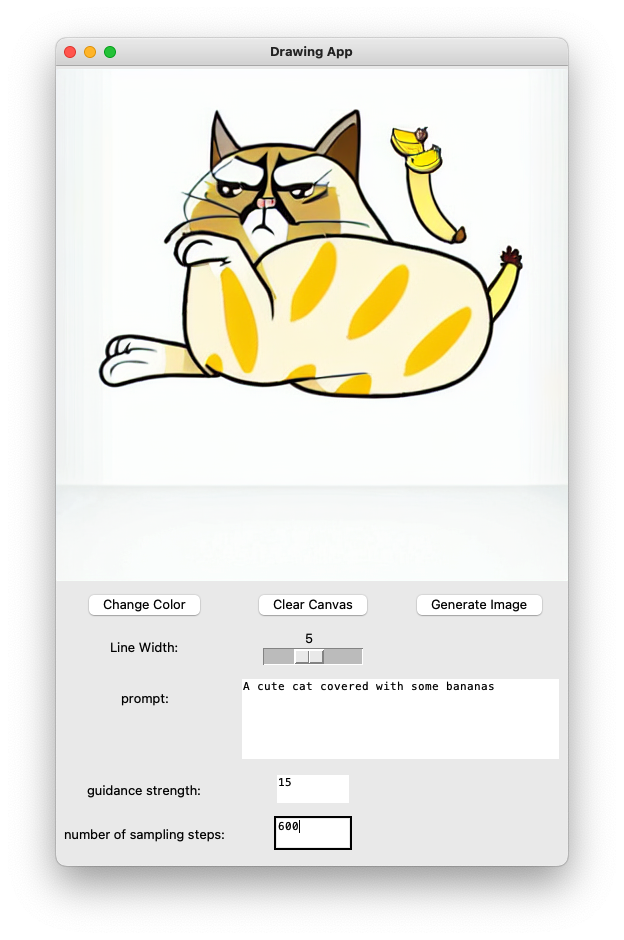
I can draw a sketch using custom color and line width, and then click the "save image" button to save the sketch image.